
앞선 글에서 제대로 다루지는 않았지만, 대부분의 웹사이트의 데이터는 그것을 제작한 회사의 고유 저작물입니다. 이것을 스크랩하고 사용, 특히 영리적으로 이용하는 것은 법적인 책임을 각오해야 할 가능성이 있음을 미리 밝힙니다. 이것을 방지하기 위해서는 해당 도메인의 robots.txt를 참고하는 것이 좋습니다. 가장 상위 도메인 (예: blog.naver.com이 아닌 www.naver.com) 확인 필수. 이걸 어기면 당장 쇠고랑 차고 어떻게 되는 것은 아닌데, 네이버의 경우 십몇년 전에 일본 진출 과정에서 네이버봇이 robots.txt를 무시하는 크롤러를 사용한 이유로 시장에서 퇴출되다시피 했었던 전례가 있습니다. 윤리적인 문제라고 해두죠. 저도 제 컨텐츠를 무단복사(불펌)하는 것은 싫고 대부분 사람들이 그러니까요.
대법원 "웹사이트 무단 크롤링은 불법"
웹사이트 콘텐츠를 긁어오는 '크롤링'을 이용해 확보한 콘텐츠를 자신의 영업에 무단 사용하는 것은 데이터베이스(DB)권 침해 행위라는 대법원 판단이 나왔다. 이는 온라인 웹사이트를 운영하는
news.bizwatch.co.kr
사람인, 잡코리아 웹사이트 크롤링 했다가… - Byline Network
2005년 지금은 사라진 검색엔진 엠파스가 '열린검색'이라는 서비스를 출시한 적이 있다. 이는 검색어를 입력하면 네이버, 다음, 야후, 네이트 등 경쟁 사이트의 DB에 담겨있는 정보까지 보여주는
byline.network
// https://www.naver.com/robots.txt
User-agent: * 모든 유저에게
Disallow: / 모든 하위 url의 크롤러 접근을 제한합니다.
Allow : /$ (네이버뉴스 크롤러 만들기 그만 좀 올리세요..)
(이것이 구글링할 때 네이버 블로그 검색 안 뜨는 이유)
// https://brunch.co.kr/robots.txt
User-agent: * 모든 유저에게
Allow: / 모든 하위 url의 크롤러 접근을 허합니다.
(단 개별 게시물의 저작권은 게시자에게 있음.)
// https://www.maxmovie.com/robots.txt
사랑해요 맥스무비 (처음 이용해봄)
User-agent: * 모든 유저에게
Allow: / 모든 하위 url 크롤러 접근을 제한합니다.
Disallow:/admin/ (관리자 페이지만 접근 제한, 하라고 해도 못하는데요;)
이렇게 간단한 robots.txt를 가진 사이트들도 있지만,
일부 크롤러(네이버봇, 예티, 구글봇 등)를 특정해 검색사이트에서의 접근만 허용하거나,
하위 도메인 하나하나를 disallow 해놓고 마지막에 Allow: / 이렇게 되어있는 사이트들도 있습니다.
그리고 어쩌면 당연하지만, 대부분의 사이트들이 사이트의 저작물을 보호하고
서버를 보호하기 위해 크롤러를 차단하고 있습니다. 당장 어긴다고 추적당해서 잡혀가는건 아니곘지만,
윤리적인 문제이고, 실제로 동종 업계의 정보를 크롤링한 회사들
(야놀자 크롤링한 여기어때, 잡코리아 크롤링한 사람인 등등)이 벌금을 낸 사례도 있으니
웬만하면 robots.txt를 확인합시다!!!이 게시물에서는 파이썬 라이브러리 requests와 BeautifulSoup4를 통해 게시물의 소스를 스크랩하고, 이것을 페이지의 html을 분해(파싱)해 필요한 정보를 다루는 것에 집중했습니다. 자, 다음의 코드를 이해하실 수 있으신가요? 이 정도의 코드는 이해 가능하셔야 이 게시물을 이해하는데 무리가 없습니다. 어떤 단어가 거꾸로 해도 똑같은 단어인지 확인해주는 함수인데, 기본적인 반복문과 조건문은 이해할 수 있어야 한다는 뜻입니다.
def is_palindrome(word):
for left in range(len(word) // 2):
right = len(word) - left - 1
if word[left] != word[right]:
return False
return True
# 테스트
print(is_palindrome("racecar"))
print(is_palindrome("stars"))
print(is_palindrome("토마토"))
print(is_palindrome("kayak"))
print(is_palindrome("hello"))우리의 Python에는 requests라는 urllib의 상위버전 같은 라이브러리가 있습니다.
파이참이나 VSCode를 켜고, (저는 파이참으로 하겠습니다.) 터미널을 켜주세요.
pip3 install requests
터미널에 requests가 금방 설치됩니다. 그리고 이 코드를 그대로 따라해봅시다. 이해보다 실행 먼저!
import requests
r = requests.get('https://brunch.co.kr/')
print(r.status_code) # 200
print(r.headers['content-type']) # text/html;charset=utf-8
print(r.encoding) # utf-8
print(r.text)오른쪽에 주석으로 적어둔 값들이 출력되고, 페이지의 소스가 좍 출력되지요?
간단한 코드지만 정상 동작하는 모습이 마음에 듭니다.
파이썬을 공부하셨다 해도 html,css,js를 공부하지 않으셨다면, 웹스크래핑을 하는 과정이 조금 험난할 수 있습니다. 중간중간에 막히는 부분들이 있다면 언제든 MDN 등을 탐색할 준비를 해놓아야 합니다.

자 그렇다면 이제 우리의 아름다운 수프를 설치해봐요.
pip3 install bs4
뷰티풀수프의 4번째 버전이라 생각하시면 됩니다. 아마 설치해보시면 bs 뿐만 아니라 이 라이브러리가 의존하는 (필요로 하는) 다른 라이브러리도 함께 설치될 것입니다. 물론 pip install BeautifulSoup라고 입력해도 설치는 되지만, 이쪽이 더 안전합니다. 자 그럼 다음 과정으로 가시죠.
import requests
from bs4 import BeautifulSoup
r = requests.get('https://brunch.co.kr/')
print(r.status_code)
print(r.headers['content-type'])
print(r.encoding)
response = r.text
soup = BeautifulSoup(response, 'html.parser')
print(soup)음.. 아까랑 똑같은 내용 아니냐구요? 자세히 봐야 보인다. 조금은 다르다. 더 아름답지 않은가...
이런 것 하자고 라이브러리 하나 더 설치한 것 아니니까 본론으로 갑시다.
글 초반에서 언급했지만 브런치를 사용하는 것은 robots.txt에서 크롤러의 접근을 허용했기 때문입니다. 많이들 예시로 사용하는 네이버뉴스, 지니뮤직 등은 사실 크롤러의 접근을 허용하지 않아요.(지니뮤직은 네이버봇, 예티 등 메이저 크롤러들만 접근 허용) 스크래핑에 대한 지식이 부족한 상태에서 무턱대고 리퀘스트만 날리는 것은 좋은 행동이 아닙니다. 해당 사이트는 무효한 트래픽이 단시간에 다수 쌓이는 것이라 당연히 좋아하지 않아요...
BeautifulSoup을 이용해 파싱한 soup은 프린트해서 살펴보면 requests의 리턴값.text와 크게 다를 것 없어 보이지만, 이것은 사실 파싱된 객체입니다. 그러니 당연히 객체에 속한 메소드들이 있어요. 그 중에서 자주 다룰 만한 것은
- select(), select_one()
- find(), find_all()
요 네가지 정도입니다. 수프에서 건더기를 건져먹듯이 필요한 태그를 골라 집어먹는 메소드들이예요. select()는 find_all()과 비슷하고, find()는 select_one()과 비슷합니다. 전자는 태그들의 배열을(순회 가능한), 후자는 가장 첫번째 해당 태그를 가져옵니다(없으면 None). find*와 select*는 약간의 차이점이 있습니다. 둘의 차이는 이따가 말씀드릴게요.
자 일단 스크랩하고 싶은 사이트를 크롬에서 열고, 개발자도구를 엽니다. 그리고 element 탭에서 타겟 태그에 마우스 오른쪽 버튼을 클릭하고 Copy > Copy Selector 를 클릭합니다. 해당 엘리먼트에 접근하기 위한 선택자가
#resultArticle > div > div.result_article > div.wrap_article_list > ul > li:nth-child(1)
이런 식으로 복사됩니다.
CSS 선택자에 대해서 이론적인 부분은 여기를 클릭해서 확인해주세요. 간단하게는 #은 id라고 하는 (보통) 유일한 태그를, .은 class라고 하는 것을 선택하는 선택자입니다. 만약 어떠한 태그가
<input type="text" id="text-input" class="name form-text"/>
이런 식으로 쓰여져 있다면 해당 태그를 선택하기 위해서는 #text-input 이라고 입력하거나(보통 id는 유일한 이름인 경우가 많으니 이러면 확실한 특정이 되겠죠), .name.form-text라고 입력하면 됩니다. 더 확실하게, 나는 input 태그를 선택하고 싶다! 하면 input.name.form-text라고 선택하면 됩니다. 또, 선택자를 복사하면 일반적으로 해당 태그가 페이지에서 몇번째 태그인지 표시가 됩니다. 이를테면 위 선택자의 li:nth-child(1)은 #resultArticle라는 아이디를 가진 태그의 자식 태그인 div 의 자식 태그인 result_article라는 클래스를 가진 div 의 자식 태그인 wrap_article_list 라는 클래스를 가진 div의 자식 태그 ul 의 첫번째 li 태그입니다. 참 쉽죠? 이렇게 저는 이 페이지에서
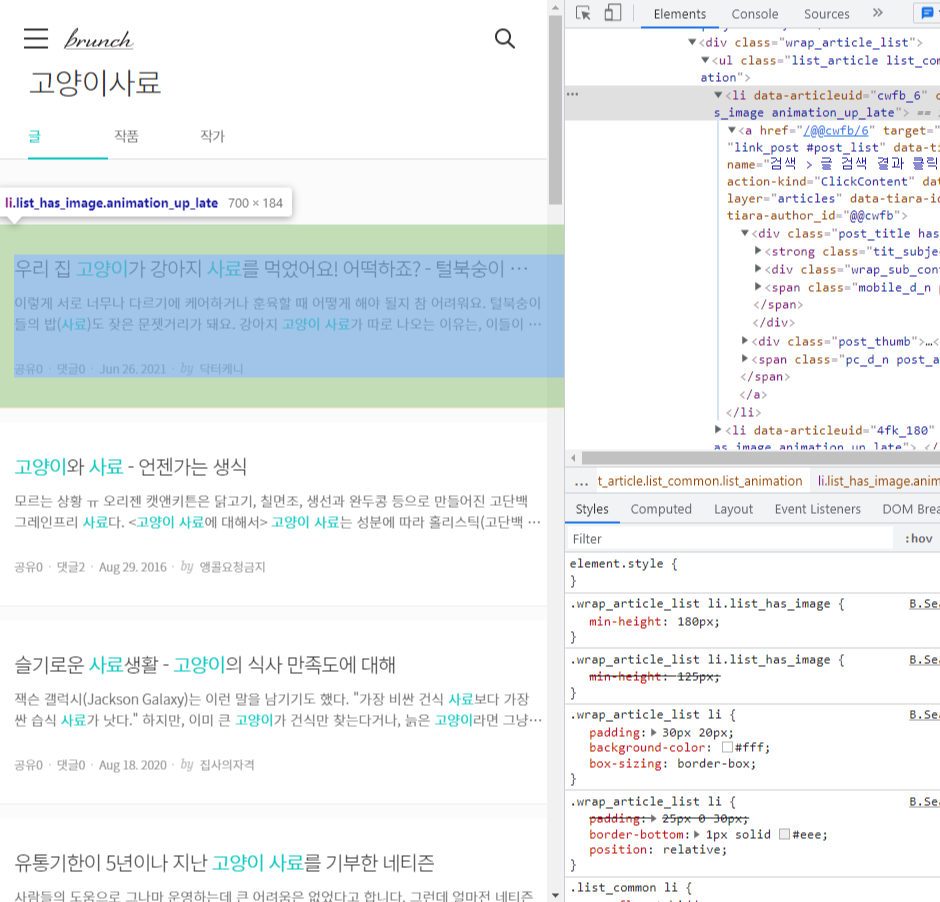
이 글에 대한 정보를 선택했습니다. 물론 스크랩하고자 하는 것은 이 글의 제목과 간단한 소개글, 작성자 등의 정보이지만, 그것은 이 태그의 선택자에서 다시 한번 더 선택자를 사용하면 더 간편합니다. 그리고 li뒤의 n번째 자식 태그 부분을 지워줍니다. 왜냐하면 모든 검색된 글의 목록을 다 가져오고 싶으니까요. 그러면 코드는 이런 상태가 됩니다.
import requests
from bs4 import BeautifulSoup
r = requests.get('https://brunch.co.kr/search?q=%EA%B3%A0%EC%96%91%EC%9D%B4%EC%82%AC%EB%A3%8C')
print(r.status_code)
print(r.headers['content-type'])
print(r.encoding)
response = r.text
soup = BeautifulSoup(response, 'html.parser')위에서 말씀 드렸듯이 select는 해당 선택자를 가진 모든 태그를 선택합니다. 그러니까, 만약 다른 글들도 이 글과 같은 태그 구조에 있다면 (보통은 그렇겠죠?) 검색된 모든 글들이 어떠한 soup의 태그 선택 객체로 리스트화됩니다. 그러니까 우리는 페이지의 소스 안에서 리스트의 내용을 순회(반복)할 필요가 있습니다. 각 글의 제목, 소개글, 작성자, 그리고 url 등을 가져와볼까요?
여기서 li:nth-child(1)까지는 아까 이미 articles라는 변수에 리스트형태로 담았으니, 각 리스트의 항목(글 정보)마다 해당하는 정보를 선택할 필요가 있습니다. 그러니까 이 뒤의 a 태그부터만 가지고 코드를 써도 되겠네요. 자 한번 코드를 이렇게 완성..해볼까요?
import requests
from bs4 import BeautifulSoup
r = requests.get('https://brunch.co.kr/search?q=%EA%B3%A0%EC%96%91%EC%9D%B4%EC%82%AC%EB%A3%8C')
print(r.status_code)
print(r.headers['content-type'])
print(r.encoding)
response = r.text
soup = BeautifulSoup(response, 'html.parser')
articles = soup.select('#resultArticle > div > div.result_article > div.wrap_article_list > ul > li')
print(articles)
for article in articles:
url = article.select_one('a').get('href')
title = article.select_one('a > div.post_title.has_image > strong').get_text()
content = article.select_one('a > div.post_title.has_image > div').get_text()
author = article.select_one('a > div.post_title.has_image > span > span:nth-child(10)').get_text()
print(url, title, content, author)get메소드는 해당 태그의 속성 중 get()의 파라미터의 문자열과 일치하는 <a href="이 안의 값">을 가져오는 메소드입니다. select나 find_all 메소드의 값은 리스트이기때문에 바로 접속할 수 없고 반복문을 통해서만 접근할 수 있어요. 자 코드를 한번 실행해 볼까요?

이게.. 머선 129..?? 사실 저는 알고있었습니다 후훗(?) 저에 대한 혐오를 멈추어주세요 해명하겠습니다.
뷰티풀숲은 설명한 바와 같이 어지럽게 펼쳐져있는 코드들을 깔끔하게 파싱해서 원하는 태그를 골라 원하는 값을 가져올 수 있는 너무나 가볍고 좋은 도구입니다!
그러나
뷰티풀숲과 함께 사용한 requests에 다소 문제점이 있어요. 그러니까, 이 라이브러리는 get()메소드를 사이트에 보내고, 그 즉시 사이트의 응답을 가져옵니다. "즉시"예요. 이게 무슨 말이냐구요? 컴퓨터는 정말 성격이 급한 아이입니다. 잠깐 사이트에 들어가서 소스를 가져와야하는데, 그 사이트가 유저가 접속한 후에 화면에 요소들을 표시하기 시작하는 "동적 웹"이라면, 그것을 불러오기 전의 껍데기만 가져와 버린다는 것이죠... 물론 리퀘스츠도 쓸모가 많은 라이브러리이지만, 웹사이트와 원활하게 소통을 한다기 보다는 요청을 보내는 일에 더 익숙한 아이예요. 그래서 이런 장벽에 가로막힌 것입니다. 그래서 위에 robots.txt를 소개하면서 맥스무비의 robots.txt를 명시한 것입니다. 일단 한번 해보시죠.
import requests
from bs4 import BeautifulSoup
request= requests.get('https://www.maxmovie.com/review')
# print(r.status_code)
# print(r.headers['content-type'])
# print(r.encoding)
response = request.text
soup = BeautifulSoup(response, 'html.parser')
articles = soup.select('li.content.clearfix')
for article in articles:
link = article.select_one('span.imgBox.floatLeft > a').get('href')
title = article.select_one('span.textBox.floatLeft > a:nth-child(1) > h4').get_text()
img_src = article.select_one('span.imgBox.floatLeft > a > span').get('style')
upload_date = article.select_one('span.textBox.floatLeft > span').get_text()
reporter = article.select_one('span.textBox.floatLeft > span > a').get_text()
print(link, title, img_src, upload_date, reporter)코드를 살짝 설명해 드리자면, select()는 특정한 선택자를 찾아냅니다. 개발자도구에서 해당 <li> 태그를 Copy Selector 클릭하면 "#__next > div > div.Section__MarginWrap-hftnb5-0.fhFgrr > section > div.MainArticle__MainCon-e184wq-0.hJcjXi > article > div.MainNews__MainContents-xyx6gc-0.epqbZ > div > ul > ul > div:nth-child(1) > li" 이렇게 길-다란 선택자가 출력되는데, 물론 이렇게 그대로 사용해도 되지만, (대신 :nth-child(1)은 해당 컨텐츠 하나만 픽하는 것이니까 지워줘야겠죠?) 페이지를 잘 분석해 보니, 모든 li태그가 class="content clearfix" 속성을 가지고 있군요. 클래스를 두개나 쥐어준 것을 보면 이 선택자가 해당 요소들을 잘 특정해 줄거라는 예감이 듭니다.
이어서 각 기사들마다, 제목, 작성한 기자, 업로드 일자, 기사 이미지들을 가져옵니다. <li>태그의 하위태그들을 특정할 것이니, 각 아티클 안에서 해당 정보들을 가져올 수 있도록, article.select_one()에 하위 선택자를 넣어줍니다. 그리고 우리가 원하는 값을 가져올 수 있도록 get_text()와 get(attr)을 적절히 사용해줍니다. 자 출력값을 볼까요?
>>> /news/432169 [리뷰] ‘그린 나이트’ 지적 허영심 충족 시키는 매혹적인 판타지의 짜릿함 background-image:url(https://maxmovie.cdnsave.com/images/1628498706998m8nzW.png);background-size:cover 12시간 전 · 위성주 기자 위성주 기자
>>> /news/432161 [4DX 리뷰] ‘귀문’ 무서움에 재미 더해진 체험형 공포 영화 background-image:url(https://maxmovie.cdnsave.com/images/1628039929478bslb5.png);background-size:cover 08월 04일 · 위성주 기자 위성주 기자
>>> /news/432158 [리뷰] ‘싱크홀’ 온 가족 함께 즐길 부성애 듬뿍 코미디 background-image:url(https://maxmovie.cdnsave.com/images/1627961908063tB2FP.png);background-size:cover 08월 03일 · 위성주 기자 위성주 기자
>>> /news/432156 [리뷰] ‘생각의 여름’ 詩를 닮은 영화로 그리는 현실의 청춘 background-image:url(https://maxmovie.cdnsave.com/images/1627911734134aBjqj.jpg);background-size:cover 08월 05일 · 위성주 기자 위성주 기자
>>> /news/432144 [리뷰] ‘보스 베이비 2’ 전편보다 아쉽지만 귀여움은 여전해 background-image:url(https://maxmovie.cdnsave.com/images/1627522942040xityC.png);background-size:cover 07월 29일 · 위성주 기자 위성주 기자
>>> /news/432140 [리뷰] ‘프리 가이’ AI 시대 발맞춘 신선한 소재의 힘 background-image:url(https://maxmovie.cdnsave.com/images/1627384621297l1PTE.png);background-size:cover 08월 06일 · 위성주 기자 위성주 기자
>>> /news/432132 [리뷰] 궁금증 해소 아닌 폭발 시키는 ‘킹덤: 아신전’ background-image:url(https://maxmovie.cdnsave.com/images/1627032393597XxGWz.png);background-size:cover 07월 23일 · 위성주 기자 위성주 기자
>>> /news/432130 [리뷰] ‘모가디슈’ 재미만큼 돋보이는 한계…한국형 상업 영화의 정석 background-image:url(https://maxmovie.cdnsave.com/images/1627010244575kpxCn.png);background-size:cover 07월 23일 · 위성주 기자 위성주 기자음 어떤가요? 뭔가 조금 아쉽나요? 각각의 출력값을 들여다 봅시다.
- 각 기사의 href 값은 완전한 전체 url이 아니라, 도메인에서 하위 주소만을 담고 있네요. 사실 흔한 경우입니다. 이런 경우에 우리가 처음 robots.txt를 확인했던 메인페이지에서 이 페이지로 내려가는 것이니 앞에 maxmovie.com을 붙여주기만 하면 되겠네요.
- 제목은 깔끔하게 잘 잡혀왔군요 마음에 듭니다.
- 이미지 태그는.. 흠 쪼끔 마음에 안드네요. 보통은 <img src="">태그 형식으로 되어 있으면 src만 딱 가져오면 되는데, 이 페이지는 style 태그로 인라인 css를 삽입해 정해진 div 태그의 백그라운드이미지로 삽입했군요. 이것도 앞의 backgroun-image... 부분을 잘라내고, 뒤의 background-size:cover;도 잘라내면 깔끔하게 이미지태그만 가져올 수 있겠습니다.
- 기사에 대한 정보(작성일자, 기자 이름)이 담긴 태그 안에 기자 이름이 있으니 이름이 두번 출력되었군요. (이 사이트는 기자분이 위성주 기자님 한분인가요..?) 해당 문자열도 우리가 원하는 정보만 잘라서 사용할 수 있도록 코드를 조작해 보겠습니다.
- 또 한가지 아쉬운 점이 있긴 하네요. 사이트에서 스크롤을 내려보니 스피너가 돌면서 조금 더 많은 기사가 로딩되는데, 성질급한 리퀘스츠는 이걸 기다려주지 않고 당장 보이는 것만 가져왔나보네요. 기사 8개만 가져왔군요.
마지막 아쉬운 점을 빼고 일단 코드를 수정해보겠습니다.
import requests
from bs4 import BeautifulSoup
target_url = 'https://www.maxmovie.com'
request= requests.get(target_url + '/review')
# print(r.status_code)
# print(r.headers['content-type'])
# print(r.encoding)
response = request.text
soup = BeautifulSoup(response, 'html.parser')
articles = soup.select('li.content.clearfix')
for article in articles:
link = target_url + article.select_one('span.imgBox.floatLeft > a').get('href')
title = article.select_one('span.textBox.floatLeft > a:nth-child(1) > h4').get_text()
img_src = article.select_one('span.imgBox.floatLeft > a > span').get('style').replace('background-image:url(', '').replace(');background-size:cover', '')
upload_date = article.select_one('span.textBox.floatLeft > span').get_text().split(' · ')[0]
reporter = article.select_one('span.textBox.floatLeft > span > a').get_text()
print(link, title, img_src, upload_date, reporter)출력값
>>> https://www.maxmovie.com/news/432169 [리뷰] ‘그린 나이트’ 지적 허영심 충족 시키는 매혹적인 판타지의 짜릿함 https://maxmovie.cdnsave.com/images/1628498706998m8nzW.png 12시간 전 위성주 기자
>>> https://www.maxmovie.com/news/432161 [4DX 리뷰] ‘귀문’ 무서움에 재미 더해진 체험형 공포 영화 https://maxmovie.cdnsave.com/images/1628039929478bslb5.png 08월 04일 위성주 기자
>>> https://www.maxmovie.com/news/432158 [리뷰] ‘싱크홀’ 온 가족 함께 즐길 부성애 듬뿍 코미디 https://maxmovie.cdnsave.com/images/1627961908063tB2FP.png 08월 03일 위성주 기자
>>> https://www.maxmovie.com/news/432156 [리뷰] ‘생각의 여름’ 詩를 닮은 영화로 그리는 현실의 청춘 https://maxmovie.cdnsave.com/images/1627911734134aBjqj.jpg 08월 05일 위성주 기자
>>> https://www.maxmovie.com/news/432144 [리뷰] ‘보스 베이비 2’ 전편보다 아쉽지만 귀여움은 여전해 https://maxmovie.cdnsave.com/images/1627522942040xityC.png 07월 29일 위성주 기자
>>> https://www.maxmovie.com/news/432140 [리뷰] ‘프리 가이’ AI 시대 발맞춘 신선한 소재의 힘 https://maxmovie.cdnsave.com/images/1627384621297l1PTE.png 08월 06일 위성주 기자
>>> https://www.maxmovie.com/news/432132 [리뷰] 궁금증 해소 아닌 폭발 시키는 ‘킹덤: 아신전’ https://maxmovie.cdnsave.com/images/1627032393597XxGWz.png 07월 23일 위성주 기자
>>> https://www.maxmovie.com/news/432130 [리뷰] ‘모가디슈’ 재미만큼 돋보이는 한계…한국형 상업 영화의 정석 https://maxmovie.cdnsave.com/images/1627010244575kpxCn.png 07월 23일 위성주 기자훨씬 깔끔한 결과물을 얻었습니다. 난이도가 갑자기 높아질까봐 간단한 replace 메소드와 split 메소드 정도만 사용했는데, 보기 편하고 좋네요. 자 그럼 남아있는 약간의 찝찝함을 해결해보겠습니다.
결과물을 좀 늘려볼까요? 음, 당장 사이트에서 스크롤을 해야 로딩되는 게시물들을 가져올 만한 방법이 현재 상황에선 떠오르지 않네요. 그럼 이건 어떨까요? 사이트의 탭을 보니 인터뷰/리뷰/기획/OTT 등이 보이는데, 기사의 구조가 비슷해 보입니다. 우리 이런 경우에 반복문을 돌릴 수 있을 것 같죠? 한번 해보겠습니다.
import requests
from bs4 import BeautifulSoup
target_url = 'https://www.maxmovie.com' # 베이스 url을 변수로 지정했어요!
target_categories = ['/review', '/interview', '/plan', '/ott'] # review 탭과 유사한 탭들만 모았어요!
for category in target_categories:
request= requests.get(target_url + category)
# print(r.status_code)
# print(r.headers['content-type'])
# print(r.encoding)
response = request.text
soup = BeautifulSoup(response, 'html.parser')
articles = soup.select('li.content.clearfix')
for article in articles:
link = target_url + article.select_one('span.imgBox.floatLeft > a').get('href')
title = article.select_one('span.textBox.floatLeft > a:nth-child(1) > h4').get_text()
img_src = article.select_one('span.imgBox.floatLeft > a > span').get('style').replace('background-image:url(', '').replace(');background-size:cover', '')
upload_date = article.select_one('span.textBox.floatLeft > span').get_text().split(' · ')[0]
reporter = article.select_one('span.textBox.floatLeft > span > a').get_text()
print(link, title, img_src, upload_date, reporter)출력값은 최소 4배는 늘었겠죠?
>>> https://www.maxmovie.com/news/432169 [리뷰] ‘그린 나이트’ 지적 허영심 충족 시키는 매혹적인 판타지의 짜릿함 https://maxmovie.cdnsave.com/images/1628498706998m8nzW.png 13시간 전 위성주 기자
>>> https://www.maxmovie.com/news/432161 [4DX 리뷰] ‘귀문’ 무서움에 재미 더해진 체험형 공포 영화 https://maxmovie.cdnsave.com/images/1628039929478bslb5.png 08월 04일 위성주 기자
>>> https://www.maxmovie.com/news/432158 [리뷰] ‘싱크홀’ 온 가족 함께 즐길 부성애 듬뿍 코미디 https://maxmovie.cdnsave.com/images/1627961908063tB2FP.png 08월 03일 위성주 기자
>>> https://www.maxmovie.com/news/432156 [리뷰] ‘생각의 여름’ 詩를 닮은 영화로 그리는 현실의 청춘 https://maxmovie.cdnsave.com/images/1627911734134aBjqj.jpg 08월 05일 위성주 기자
>>> https://www.maxmovie.com/news/432144 [리뷰] ‘보스 베이비 2’ 전편보다 아쉽지만 귀여움은 여전해 https://maxmovie.cdnsave.com/images/1627522942040xityC.png 07월 29일 위성주 기자
>>> https://www.maxmovie.com/news/432140 [리뷰] ‘프리 가이’ AI 시대 발맞춘 신선한 소재의 힘 https://maxmovie.cdnsave.com/images/1627384621297l1PTE.png 08월 06일 위성주 기자
>>> https://www.maxmovie.com/news/432132 [리뷰] 궁금증 해소 아닌 폭발 시키는 ‘킹덤: 아신전’ https://maxmovie.cdnsave.com/images/1627032393597XxGWz.png 07월 23일 위성주 기자
>>> https://www.maxmovie.com/news/432130 [리뷰] ‘모가디슈’ 재미만큼 돋보이는 한계…한국형 상업 영화의 정석 https://maxmovie.cdnsave.com/images/1627010244575kpxCn.png 07월 23일 위성주 기자
>>> https://www.maxmovie.com/news/432162 [인터뷰] ‘싱크홀’ 김성균 “선보일 수 있었던 최고의 결과물” https://maxmovie.cdnsave.com/images/1628053959268ZDC8G.png 08월 04일 위성주 기자
>>> https://www.maxmovie.com/news/432149 [인터뷰] ‘킹덤: 아신전’ 김은희 작가 “공존, 상생 사회 꿈꿔” https://maxmovie.cdnsave.com/images/1627629751006KV6EN.png 07월 30일 위성주 기자
>>> https://www.maxmovie.com/news/432146 [인터뷰] ‘모가디슈’ 구교환 “극장 가는 것은 여전히 낭만적” https://maxmovie.cdnsave.com/images/1627544450908VIr8G.png 07월 29일 위성주 기자
>>> https://www.maxmovie.com/news/432142 [인터뷰] ‘모가디슈’ 허준호 “류승완 감독은 영화에 미쳤다” https://maxmovie.cdnsave.com/images/1627468794937S0vYF.png 07월 28일 위성주 기자
>>> https://www.maxmovie.com/news/432135 [인터뷰] ‘모가디슈’ 김윤석 “불가능한 도전…반경 5km 넘는 도시 전체 세팅해” https://maxmovie.cdnsave.com/images/16272843234725lURl.png 07월 26일 위성주 기자
>>> https://www.maxmovie.com/news/432131 [인터뷰] ‘방법: 재차의’ 연상호 작가 “기괴함과 유치함은 한 끗 차이” https://maxmovie.cdnsave.com/images/1627014691981ykEoN.png 07월 23일 위성주 기자
>>> https://www.maxmovie.com/news/432113 [인터뷰] ‘랑종’ 무당役 싸와니 우툼마 “영화 의미 해석은 관객의 몫” https://maxmovie.cdnsave.com/images/1626745942789cz9pf.png 07월 20일 위성주 기자
>>> https://www.maxmovie.com/news/432091 [MAX 인터뷰] ‘제8일의 밤’ 김태형 감독 “개인 내면의 번민과 번뇌 표현” https://maxmovie.cdnsave.com/images/1626082253573NdxjO.png 07월 12일 위성주 기자
>>> https://www.maxmovie.com/news/432166 [현장 종합] ‘프리 가이’ 라이언 레이놀즈 “우리 사회와 문화 반영하는 작품” https://maxmovie.cdnsave.com/images/1628213516372Dvbu6.png 08월 06일 위성주 기자
>>> https://www.maxmovie.com/news/432164 [이번 주 뭘볼까] ‘더 수어사이드 스쿼드’-’킬러의 보디가드 2: 킬러의 와이프’-’그린 나이트’-’잘리카투’ https://maxmovie.cdnsave.com/images/1628130330592lUbPq.jpg 08월 06일 김희주 기자
>>> https://www.maxmovie.com/news/432159 [현장 종합] ‘귀문’ 김소혜 “보고 나면 영혼 나갈 것 같은 영화” https://maxmovie.cdnsave.com/images/16279751798039vMM0.png 08월 03일 위성주 기자
>>> https://www.maxmovie.com/news/432155 [현장 종합] ‘싱크홀’ 차승원 “돈 많이 들어간 티가 나는 영화” https://maxmovie.cdnsave.com/images/1627899140617ED7Q2.png 08월 02일 위성주 기자
>>> https://www.maxmovie.com/news/432153 [현장] ‘싱크홀’ 김성균 “평범한 ‘보통 사람’ 연기해…아들과 함께한 느낌” https://maxmovie.cdnsave.com/images/16278978235426Bi4B.png 08월 02일 위성주 기자
>>> https://www.maxmovie.com/news/432152 [현장] ‘더 수어사이드 스쿼드’ 제임스 건 감독 “마블 보다 더 자유로웠던 현장” https://maxmovie.cdnsave.com/images/1627876581057S7MOK.png 08월 02일 위성주 기자
>>> https://www.maxmovie.com/news/432145 [이번 주 뭘볼까] ‘모가디슈’-’방법: 재차의’-’정글 크루즈’-’우리, 둘’ https://maxmovie.cdnsave.com/images/1627534597982WLZgF.jpg 07월 30일 김희주 기자
>>> https://www.maxmovie.com/news/432141 [현장 종합] ‘암살자들’ 라이언 화이트 감독 “김정남 암살 사건 본질에 주목” https://maxmovie.cdnsave.com/images/1627458799696xq3wi.png 07월 28일 위성주 기자
>>> https://www.maxmovie.com/news/432149 [인터뷰] ‘킹덤: 아신전’ 김은희 작가 “공존, 상생 사회 꿈꿔” https://maxmovie.cdnsave.com/images/1627629751006KV6EN.png 07월 30일 위성주 기자
>>> https://www.maxmovie.com/news/432147 [OTT] 넷플릭스 ‘D.P.’ 8월 27일 공개 확정…티저 포스터&예고편 공개 https://maxmovie.cdnsave.com/images/1627606022628jdjl7.jpg 07월 30일 이정빈 기자
>>> https://www.maxmovie.com/news/432132 [리뷰] 궁금증 해소 아닌 폭발 시키는 ‘킹덤: 아신전’ https://maxmovie.cdnsave.com/images/1627032393597XxGWz.png 07월 23일 위성주 기자
>>> https://www.maxmovie.com/news/432116 [현장 종합] 넷플릭스 ‘킹덤: 아신전’ 김성훈 감독 “다시 태어나면 장항준으로” https://maxmovie.cdnsave.com/images/1626751619876Z5YTI.png 07월 20일 위성주 기자
>>> https://www.maxmovie.com/news/432114 [현장] ‘킹덤: 아신전’ 전지현 “좀비로라도 나오고 싶었다” https://maxmovie.cdnsave.com/images/16267482930937Ivtn.png 07월 20일 위성주 기자
>>> https://www.maxmovie.com/news/432091 [MAX 인터뷰] ‘제8일의 밤’ 김태형 감독 “개인 내면의 번민과 번뇌 표현” https://maxmovie.cdnsave.com/images/1626082253573NdxjO.png 07월 12일 위성주 기자
>>> https://www.maxmovie.com/news/432088 [OTT] ‘킹덤: 아신전’ 2차 메인 포스터 공개 “올 여름, 전 세계 목마르게 할 92분” https://maxmovie.cdnsave.com/images/1626054276046tecpl.png 07월 12일 위성주 기자
>>> https://www.maxmovie.com/news/432086 [OTT] 드웨인 존슨X라이언 레이놀즈 ‘레드 노티스’ 11월 12일 넷플릭스 공개 확정 https://maxmovie.cdnsave.com/images/1625814734207HQ2Fp.jpg 07월 09일 위성주 기자와우! 너모 마음에 듭니다. 결과물도 아주 깔끔하네요.
자 그러면 이제 이 정보를 어딘가에 기록해두는 게 좋겠죠? 몽고db 같은 noSQL이나 SQL, json 등 다양한 포맷으로 데이터를 저장해 둘 수 있겠지만, 이번엔 csv를 이용해 해당 데이터를 저장해 보겠습니다. csv 라이브러리를 임포트해서 해당 정보를 저장해볼게요. 사용법은 간단합니다. 주의해야 할 것은 writerow를 작성할 때, 한 줄에 넣고 싶은 데이터를 꼭 리스트에 넣어서 작성해야 해요. 안 그러면 글자 하나하나 분리되는 참극이...
import requests
from bs4 import BeautifulSoup
import csv
with open(file='max_movie.csv', newline="", encoding='ansi', mode='w') as output_file:
writer = csv.writer(output_file)
writer.writerow(['link', 'title', 'img_src', 'upload_date', 'reporter'])
target_url = 'https://www.maxmovie.com'
target_categories = ['/review', '/interview', '/plan', '/ott']
for category in target_categories:
request = requests.get(target_url + category)
response = request.text
soup = BeautifulSoup(response, 'html.parser')
articles = soup.select('li.content.clearfix')
for article in articles:
link = target_url + article.select_one('span.imgBox.floatLeft > a').get('href')
title = article.select_one('span.textBox.floatLeft > a:nth-child(1) > h4').get_text()
img_src = article.select_one('span.imgBox.floatLeft > a > span').get('style').replace('background-image:url(', '').replace(');background-size:cover', '')
upload_date = article.select_one('span.textBox.floatLeft > span').get_text().split(' · ')[0]
reporter = article.select_one('span.textBox.floatLeft > span > a').get_text()
writer.writerow([link, title, img_src, upload_date, reporter])
print([link, title, img_src, upload_date, reporter])with open(file='max_movie.csv', newline="", encoding='ansi', mode='w') as output_file:
이 부분은 outputfile = open(file='max_movie.csv', newline="", encoding='ansi', mode='w') 이라고 작성해도 됩니다.
대신 이렇게 할 때에는 outputfile을 마지막에 .close() 해줘야 해서 with open을 사용했어요.
프린트 결과물은 아까와 같을테니 이번엔 엑셀로 열어보겠습니다.
위의 코드에서 encoding="ansi" 이 부분은 보통은 encoding="utf-8"로 작성을 해요. 한글이 깨지지 않고 범용적인 인코딩이거든요. 근데 보통은 따로 설정을 하지 않으면 csv 파일을 utf-8 인코딩으로 저장하고 엑셀에서 열면 한글이 깨지는 경우가 있더라구요 이것을 대비하기 위해 csv 인코딩을 ansi로 했어요. 웬만하면 utf-8로 작성해주세요ㅎㅎ
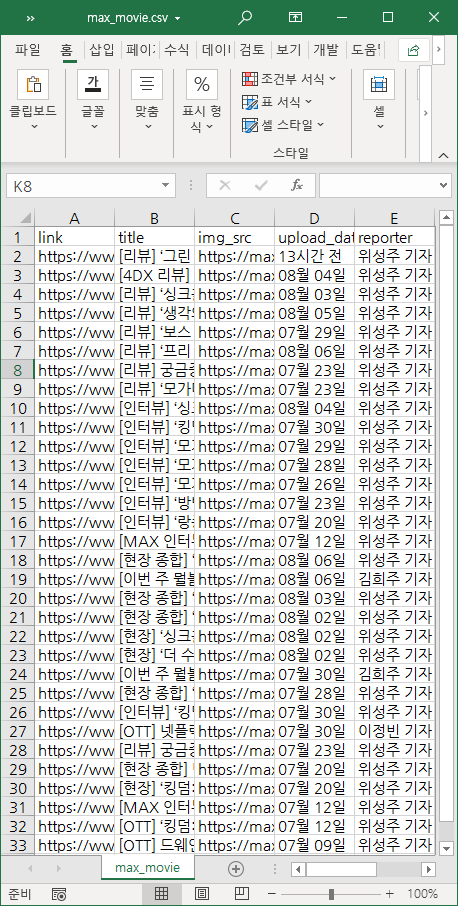
깔-끔하게 나왔죠?ㅎㅎ 어딘가 바로 써먹어도 될 것 같은 깔끔한 데이터가 나왔어요. 보통은 엑셀로 열었을 때 셀의 서식은 없는 상태로 나오니까 서식을 조금 손 보시고 엑셀로 따로 저장하셔도 됩니다...만 저는 보통 그렇게 안해요 그렇게 할 거였으면 처음부터 openpyxl이라는 엑셀 관련된 좋은 라이브러리가 있거든요. csv는 일단 속도가 매우 빠르고! 매 줄을 작성하는 것이 실시간으로 이뤄져서 마지막에 저장하는 코드가 없어도 중간에 에러가 났을때 결과물이 보존되어 있어요. 또 서식이 없으니 파일도 가벼워 나중에 이 데이터를 다시 읽는 코드를 작성할 때 다루기 편하구요ㅎㅎ 데이터를 여러 시트에 나눠서 저장하려면 opnepyxl을 사용해보세요 어렵지 않습니다ㅎㅎ 저는 32줄 코드 작성하는데 그럴 필요까지는 못 느꼈어요ㅎㅎ
제가 평소 이용해본 적도 없는 맥스무비 사이트를 이용한 것은, 현대의 웹사이트들은 대부분 사용자 경험 최적화를 위해 빈껍데기 페이지(템플릿)를 먼저 로드한 뒤 데이터를 불러와서 자리에 배치하는 형태(동적 웹페이지)인 경우가 많아 리퀘스츠 라이브러리 만으로 스크랩할 수 없는 경우가 많아요! 거기다가 robots.txt에서 크롤러의 접근을 허한 사이트를 거기서 또 걸러보면 정-말 예시로 쓸 만한 사이트가 없었습니다.... 뉴스 사이트를 쓰자니 네이버뉴스+다음뉴스 등은 robots.txt가 허락하지 않고... 허용된 언론사 홈페이지를 다루자니 뭔가 특정 정치색을 드러내는 것 같고 그래서 서윗하게 영화 매거진을 택했습니다ㅎㅎ 다음 페이지에서는 robots.txt를 거스르지 않고(윤리적인 문제입니다.) 허용된 페이지에서 동적으로 동작하는 크롤러를 만들어 보겠습니다ㅎㅎ 셀레니움이란 라이브러리를 사용할 것이예요!ㅎㅎ
'Scraping' 카테고리의 다른 글
| [파이썬으로 웹스크래핑] 에러? 또 에러?! 셀레니움으로 막힘 없이 스크랩하기 (4) | 2021.09.04 |
|---|---|
| [파이썬으로 웹스크래핑] 셀레니움 기능탐구(2) 기다려! 대기하기 (0) | 2021.08.11 |
| [파이썬으로 웹스크래핑] 셀레니움 기능탐구(1) 요소찾기 (0) | 2021.08.11 |
| [파이썬으로 웹스크래핑] 가슴이 웅장해지는 셀레니움을 araboja.. (0) | 2021.08.10 |
| [파이썬으로 웹스크래핑] 스크랩핑? 크롤링? 그게 뭘까? (0) | 2021.08.09 |




댓글