
파이썬으로 웹스크래핑을 하는 글을 몇개 썼는데, 오랜만에 이어서 하나 더 써본다. 구글에 파이썬으로 웹스크래핑(혹은 크롤링) 검색을 하면 내가 설명했던 방법들(requests, bs4, selenium)이 주로 소개되어진다. 거기에 좀 드물지만 Scrapy 정도?? 일단 나는 나보다 웹스크래핑에 익숙하지 않은 사람들을 주 독자로 생각하고 글을 쓰고 있으니 scrapy는 일단 나중으로 미루고, 간단한 스크래핑 방법에 대하여 써보고자 한다. 아주 쉬운 방법이고 법적으로도 훨씬 클린한데, 어디에나 쓸 수 있는 기술은 아니라서 잘 알려지지 않은 듯하다. 사실 이걸 스크래핑이라 불러도 되는지 모르겠다.
우선 라이브러리/모듈을 받아보자
pip install feedparser이름에서 어느정도 감이 오려나? 피드를 파싱해주는 모듈이다. 자 그럼 여기서 피드는 어떤 것을 말하는 것일까?
내가 관리하지 않는 사이트에 새 글이 떴다는 것을 나는 어떻게 알 수 있을까?
부트캠프에서 공부하고 있을 때, 다른 캠프원들의 사기진작? 목적으로 간단한 토이프로젝트로 스크래핑을 한 적이 있다. 사람들이 첫날 멤버카드에 작성한 블로그 주소를 데이터베이스에 담고, 그 주소에 일정 기간마다 방문하여 새 글이 올라왔는지 확인하고 그것을 데이터베이스에 가져와 피드 형식으로 보여주는 웹사이트였다. 반쯤은 장난으로 만들었던 것이기도 하고, 당시 파이썬 플라스크를 한참 배우다가 자바 스프링으로 넘어가는 단계였어서, 좀 더 큰 규모의 웹앱인 팀 프로젝트보다 작은 프로젝트를 스프링으로 컨버팅 해 보고 싶어서 만든 것이었다.
프로젝트 소개는 이쯤하고, 그 얘기를 왜 하냐면, 이 프로젝트의 주요 기능은 무엇일까? 피드 생성 기능? 아니 피드를 긁어오는 기능이다. 처음에는 사람들이 보통 공부 시간이 끝나는 시간인 9시나 10시 사이에 TIL(개발일지)를 올리기 때문에 그 시간대 이후에 스크랩을 해야겠다고 생각했다. 그런데 사람들은 어제 자신이 쓴 글이 왜 사이트에 올라와 있지 않냐고 물어봤다. 수업 끝나고 아홉시에 스크랩하는데 그 이후에 쓰신 건 오늘 스크랩될 거예요. 라고 답했다.
듣고 보니 사기진작? 개발일지 작성 독려? 목적에 어긋나지 않나 생각이 들었다. 그래서 하루에 두번 방문하는 것으로 크론식을 변경했다. 결과적으로 어땠냐면, 블로그를 운영하는 입장에서 방문자 수는 항상 신경쓰이는 숫자인데, 그 숫자에 내 스크래퍼가 자꾸 무효 트래픽을 쌓아주니까 사람들이 "어쩐지 블로그 방문자가 많더라니!!" 하고 어이 없어했다. 사실 하루 두번도 두번인데, 내가 코드를 짜고 있을때는 더 자주 블로그에 리퀘스트를 날리게 되어있고, 셀레니움을 사용해서 스크랩하면 이게 사람이 들어와서 보고 간 건지 아닌건지 티가 안나고 아무튼 여러 문제가 많았다.
그럼 이런 상황에는 어떻게 접근하면 좋을까?
간단하게 답부터 말하자면 RSS다.
RSS????
들어본 사람도 있고 아닌 사람도 있겠지만, 나는 네이버 블로그를 처음 만들었을 때나 싸이월드 같은걸 할때 본 뒤로 잘 본 적이 없고, 어떻게 써먹는지도 잘 몰랐다. 그런데 이게 참 괜찮은 기술이다.
RSS(Rich Site Summary)는 뉴스나 블로그 사이트에서 주로 사용하는 콘텐츠 표현 방식이다. 웹 사이트 관리자는 RSS 형식으로 웹 사이트 내용을 보여 준다. 이 정보를 받는 사람은 다른 형식으로 이용할 수 있다. RSS 리더에는 웹기반형과 설치형이 있다. - 위키백과
RSS는 어떤 사이트에 새로운 콘텐츠가 올라왔을 때 해당 사이트에 방문하지 않고, RSS서비스를 통해 리더 한 곳에서 그 콘텐츠를 이용하기 위한 방법이다. 쉽게 생각하면, 여러 언론사 사이트를 모두 방문할 필요 없이 다양한 기사를 네이버뉴스 한 곳에서 볼 수 있는 것과 같다고 보면 된다. - 나무위키꺼라
그러니까 뉴스들을 모아서 보여주는 네이버뉴스 같은 사이트는 일일이 사이트들을 방문해서 뉴스를 가져오는게 아니다. 그리고 언론사들이 각 포털 사이트마다 새로 작성한 뉴스들을 여기 있습니다 하고 보내주는 것도 아니다. 그냥 자연스레 구독과 알림설정 좋아요 하고 있는 것이다.
이게 블로그 글 퍼오는 거랑 무슨 상관이냐면, 당신의 티스토리 주소에 (아니면 내꺼에) /rss 를 입력해보라.
XML 형태로 블로그에 대한 개략적인 설명과 최근 작성한 글들이 보일 것이다.
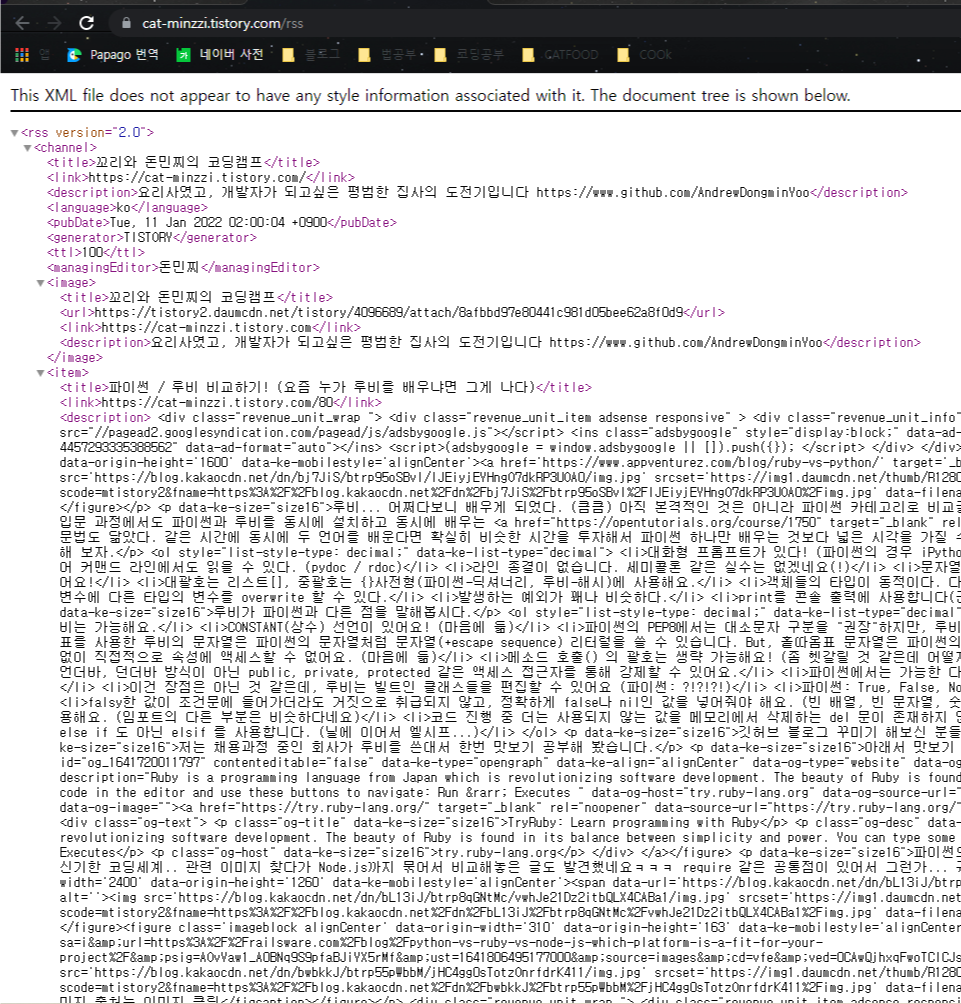
잉 나는 이런거 공개한 적이 없다 이게 뭐냐 묻는다면, 블로그 관리 탭에 들어가보자.

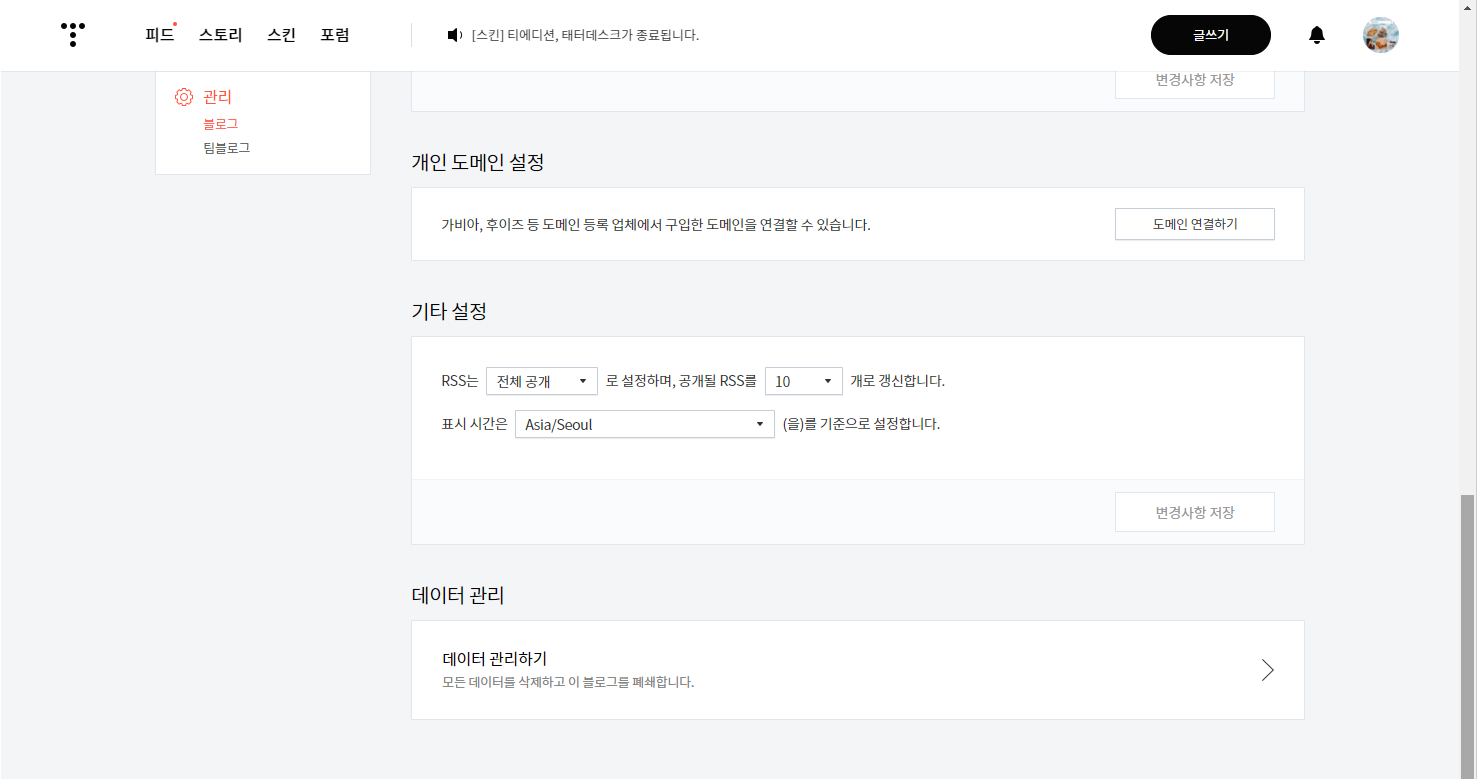
오잉 요기잉네..
몇개의 최신글을 공개할지 설정까지 해준 모습을 볼 수 있다.
그래서 여기에 있는 글들을 하루에 한번 정도만 방문해 새로운 글만 수집하면, 상대방의 방문자 트래킹에도 부담을 주지 않고, 한번에 여러 글의 개략적인 정보를 가져갈 수 있다. 제목은 물론 아티클의 주소와 사용된 이미지 주소도 가져올 수 있다.
그런데 이걸 어떻게 쓰냐면 아까 설치한 feedparser의 parse 메소드를 이용해 이 rss의 주소를 받으면, FeedParserDict 사전형 데이터로 파싱된다. 여기에서 entries 키에 들어있는 값이 XML에서 <item> 태그 안에 있는 새로운 피드 값들이다.
import feedparser
rss = feedparser.parse("https://cat-minzzi.tistory.com/rss")
entries = rss["entries"]
for entry in entries:
print(entry["title"])이렇게 간단한 코드로 이 블로그의 최신 글들을 받아볼 수 있게 된다 (그래도 직접 방문해줘....)
참고로 velog 는 https://api.velog.io/rss/@유저네임,
네이버블로그는 http://blog.rss.naver.com/유저네임.xml
다음 블로그는 http://blog.daum.net/xml/rss/유저네임
깃허브 블로그(Jekyll)나 노션 블로그는 본인들이 직접 RSS를 작성해서 등록해야 한다. 여러모로 번거롭겠지만 이게 검색 노출에도 영향을 끼치는 거라 등록해두는 것이 좋다.
참고로 많은 사이트들이 (특히 뉴스사이트) 자신들의 rss 주소를 공개하고 있고, 많은 사람들이 feedly 같은 RSS 리더기를 이용해 뉴스를 구독한다. 나만 몰랐지 나만...
'Python' 카테고리의 다른 글
| [장고웹개발] 장고와 친해져 봅시다. (부제: 요즘도 장고 쓰냐) (1) | 2022.02.15 |
|---|---|
| 내 티스토리는 무슨 키워드로 많이 유입될까??? 워드클라우드 다시 맛보기 (0) | 2022.02.11 |
| 파이썬 / 루비 비교하기! (요즘 누가 루비를 배우냐면 그게 나다) (1) | 2022.01.09 |
| [파이썬으로 웹개발] 내일배움캠프 개발일지 모음 사이트 후기 (0) | 2021.11.07 |
| 플라스크는 간단하다. 하지만 간단하기만 한 것은 아니다. (0) | 2021.10.27 |




댓글